Mickaël Tits - Data Scientist @ CETIC
Restauration d'image par réseaux de neurones profonds
Cas d'application : un ouvrage en hommage aux sportifs belges, nivellois
Mickaël Tits - CETIC - 05/11/2019
(ON-GOING WORK!)
 |
 |
Browse content
Introduction
Dans le cadre du projet DigiMIR, projet FEDER mené en collaboration entre le CETIC et Numediart, nous avons testé et comparé différentes techniques de restauration d’image basées sur de l’intelligence artificielle, et plus particulièrement sur les réseaux de neurones profonds. Ces techniques, bien qu’encore imparfaites et en plein développement, ont un intérêt réel dans différents contextes nécessitant d’améliorer la qualité d’une image. Les applications peuvent aller de la vidéo-surveillance à l’histoire et l’art, en passant par l’imagerie médicale ou satellite. De manière générale, toute image de faible qualité peut bénéficier de techniques de restauration d’image, que ce soit dû à la détérioration d’un support par le temps, ou la qualité d’acquisition d’origine (capteur low-cost ou âgé, contraintes spécifiques à un canal d’acquisition, e.g. images infrarouges, satellites, IRM), ou encore la compression numérique.
Une collaboration avec une organisation culturelle belge, le Rif tout dju, et ses contacts avec le journaliste et auteur Jean Vandendries, nous a fourni un cas d’application concret pour tester les techniques identifiées lors de notre recherche bibliographique. Grâce à ce contexte, nous démontrerons dans cet article l’intérêt de certaines techniques de restauration sur des images historiques.
A titre d’exemple, voici quelques images de champions de boxe belges originaires de Nivelles, fournies par Jean Vandendries comme échantillons de test pour ce projet.

Figure 1 - Boxeurs belges (crédits: Jean Vandendries)
Ces images présentent de nombreux défauts, dont quatre ont été retenus en particulier:
- Le bruit non-structuré (bruit blanc, ou gaussien) présent dans les images
- Le bruit structuré: des rayures horizontales et verticales
- La couleur (monochrome)
- La faible résolution
Nous avons dès lors testé et comparé différentes techniques basées sur les réseaux neuronaux permettant d’améliorer ces images. Nous avons identifié différents types de techniques, corrigeant chacune un type de défauts, et avons développé un pipeline d’opérations permettant une restauration plus “globale” des images.
Un pipeline de techniques de restauration d’image
Des techniques diverses et variées
L’état de l’art de la restauration d’image se divise actuellement en différentes techniques distinctes, permettant chacune de corriger un type particulier d’artéfacts indésirables présents dans une image, ou d’inférer artificiellement de l’information supplémentaire à l’image (telle que des couleurs, ou des détails). Dans le cadre du présent projet de recherche, nous nous sommes intéressés, jusqu’à présent, à quatre techniques en particulier:
- La suppression de bruit gaussien
- La suppression de rayures (bruit de bande - stripe noise)
- La colorisation
- La super-résolution
En pratique, une image de faible qualité présente souvent différents types de défauts, et à des degrés divers. Une image historique sera souvent limitée à une échelle de gris, une faible résolution, des artéfacts dus à la détérioration d’un support physique (tel que du papier jauni et écaillé par le temps), et à la numérisation de celui-ci. L’application individuelle des techniques susmentionnées n’aura alors qu’une portée limitée sur les possibilités de restauration de cette image. Afin de restaurer efficacement une image, il est donc nécessaire d’appliquer un ensemble de ces techniques.
Une mise en série compliquée
Dans ce projet, nous avons étudié la mise en série de ces différentes techniques, de manière à obtenir une restauration holistique d’une image. Cette mise en série n’est en réalité pas un problème trivial, car l’application d’une technique peut fortement impacter le résultat de la technique subséquente. Dans certains cas, elle peut améliorer le résultat: l’application de la super-résolution sur une image bruitée risque parfois d’augmenter les détails d’un artéfact indésirable, telle qu’une rayure, de la neige ou tout autre type de bruit. Si tel est le cas, l’application préalable d’une technique de réduction du bruit rendra plus efficace la super-résolution.
L’impact des techniques précédant la colorisation d’une image est particulièrement important également : la colorisation par réseaux de neurones profonds se base en grande partie sur l’analyse sémantique du contenu d’une image. L’algorithme apprend dans une certaine mesure à reconnaître un objet, grâce à sa forme et sa texture, lui permettant ensuite de déterminer quelle est sa couleur la plus probable. Le bruit d’une image peut rendre difficile l’analyse sémantique, et en particulier l’analyse des textures des objets. L’application d’une technique de réduction de bruit, ou d’augmentation des détails (super-résolution), peut alors faciliter la reconnaissance d’une texture.
A l’inverse, l’état de l’art de ces techniques est encore limité et imparfait, et l’application de certaines techniques peut parfois engendrer une perte significative d’information, ou la création de nouveaux artéfacts indésirables. C’est notamment le cas de la réduction de bruit gaussien, qui a souvent tendance à trop “lisser” les images, c’est-à-dire à éliminer une partie de leur texture. Ainsi par exemple, la texture poreuse d’une surface de béton, poussiéreuse d’une terre battue, ou herbeuse d’un gazon peuvent devenir identiquement lisses après application imparfaite de cette technique. Dans ce cas, la colorisation d’un jardin ou d’un mur de briques peuvent résulter en une surface grisâtre sans texture claire. A l’inverse, la super-résolution peut parfois “inventer” des détails peu réalistes, rendant la texture tout aussi ininterprétable. Dès lors, l’ajustement minutieux de la séquence et des paramètres d’un pipeline de techniques de restauration d’image devient important. Malheureusement, il est difficile, voire impossible, d’identifier un pipeline d’opérations idéal, car les résultats peuvent varier selon les caractéristiques et les défauts d’une image.
Des outils hétérogènes et incompatibles
La littérature informatique se distingue souvent par sa vaste hétérogénéité. En effet, il possible d’implémenter un même algorithme avec de nombreux outils différents, souvent incompatibles entre eux. Différents langages de programmation, différents frameworks ou librairies, ou encore différentes versions d’une librairies peuvent être utilisés, rendant difficile l’intégration dans un même programme de techniques dont les implémentations sont incompatibles entre elles.
Dans le présent contexte, les algorithmes de Deep Learning sont le plus souvent implémentés en Python. Les librairies de Deep Learning les plus connues sont en effet Tensorflow, Keras et Pytorch, toutes trois développées ou principalement utilisées en Python. Néanmoins, d’autres langages, tel que Matlab, sont aussi fréquemment utilisés. Son utilisation, bien que sans doute due partiellement à des raisons historiques, est également due à la nature du traitement d’image nécessitant de nombreux processus d’algèbre matricielle, calculs particulièrement bien supportés par Matlab. C’est notamment le cas d’un algorithme actuellement premier dans plusieurs classements de référence concernant la réduction de bruit : Multi-level Wavelet-CNN for Image Restoration - MWCNN (CVPR, 2018)
Etant donné le côté fermé d’un langage comme Matlab (programme payant, closed-source), certains de ces algorithmes sont réécrits en Python. C’est notamment le cas d’un des premiers algorithmes de réduction de bruit utilisant les réseaux de neurones profonds : Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising - DnCNN (TIP, 2017). On trouve pour celui-ci, des ré-implémentations en PyTorch et Keras.
D’autres outils sont parfois utilisés pour optimiser les performances computationnelles, permettant ainsi un traitement plus rapide des images. C’est notamment le cas des frameworks Caffe et Torch, utilisés par exemples dans les travaux suivants: Image Super-Resolution for Anime-Style Art, Residual Dense Network for Image Super-Resolution (CVPR 2018).
Des performances hétérogènes et peu réalistes
Chaque implémentation d’une technique est testée et validée différemment par son développeur. En général, les images ayant obtenus les meilleurs résultats sont utilisées pour présenter le travail. Afin de rendre plus objective la comparaison des performances des algorithmes, divers classements, basés sur des mesures standards et sur des jeux de données standards sont utilisés. Cependant, ceux-ci se limitent également à un ensemble restreint d’images d’un type particulier. On retrouve par exemple des classements sur les jeux de données URBAN100 (100 images de paysages urbains), et Manga109 (109 images d’animation). Les jeux d’images de test habituels peuvent être visualisés ici.
Le site paperswithcode.com référence de nombreux classements pour chacune des techniques évoquées plus haut. Pour la super-résolution par exemple, six classements sont actuellement référencés:
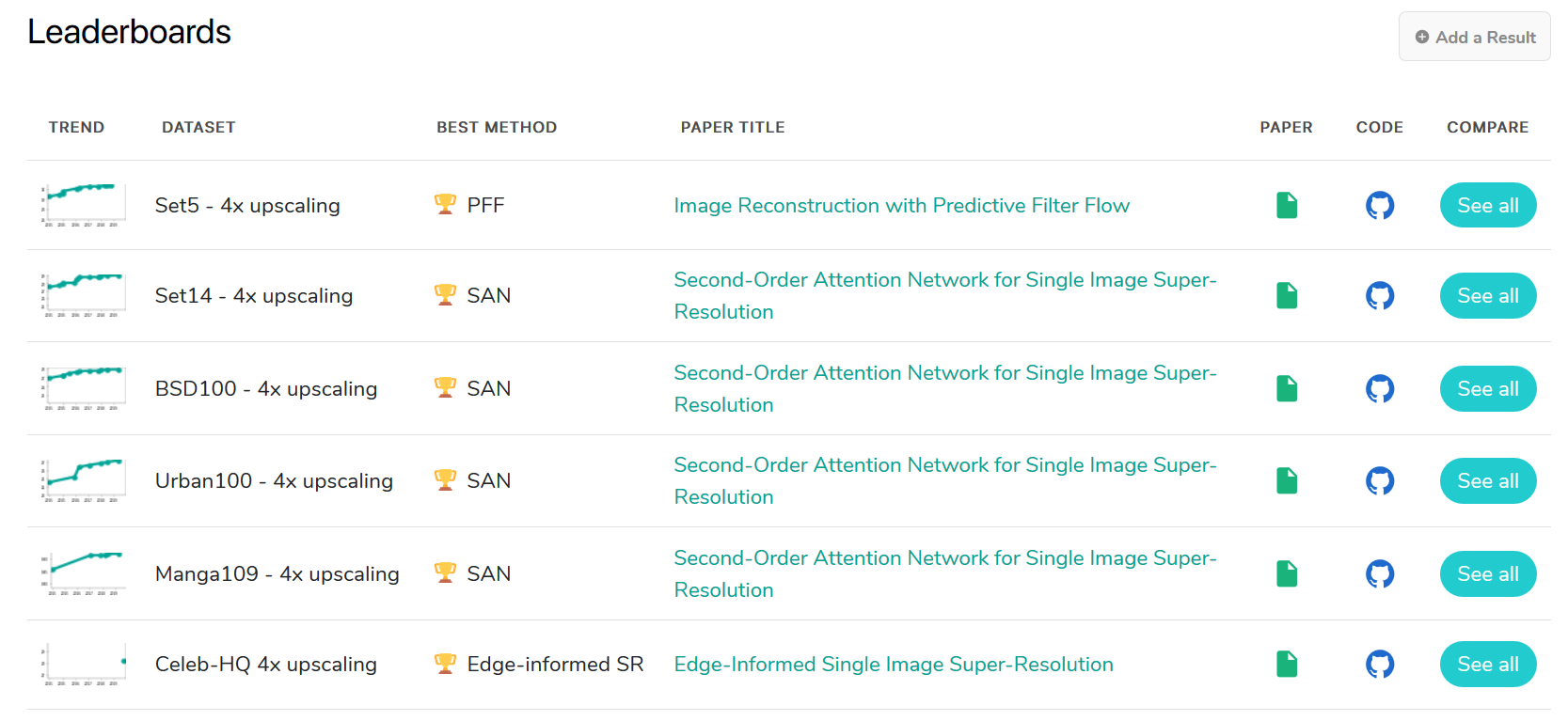
Figure 2 - Classements en super-résolution d'image - paperwithcode.com (05/11/2019)
Le classement comparant le plus grand nombre d’algorithmes est actuellement le “Set5 - 4x upscaling”, comparant les résultats sur seulement cinq images spécifiques (voir figure suivante). Cependant, les performances sur un ensemble de cinq images ne garantissent absolument pas l’efficacité sur d’autres images aux caractéristiques potentiellement très différentes. De plus, des contextes d’application typiques nécessitant de la restauration d’image (tel que des images prises par des capteurs low-cost, par des smartphones, de images nocturnes de vidéosurveillance, ou encore images historiques) ne sont pris en compte dans aucun de ces classements.

Figure 3 - Jeu de données de test Set5. (source: http://vllab.ucmerced.edu/wlai24/LapSRN/ )
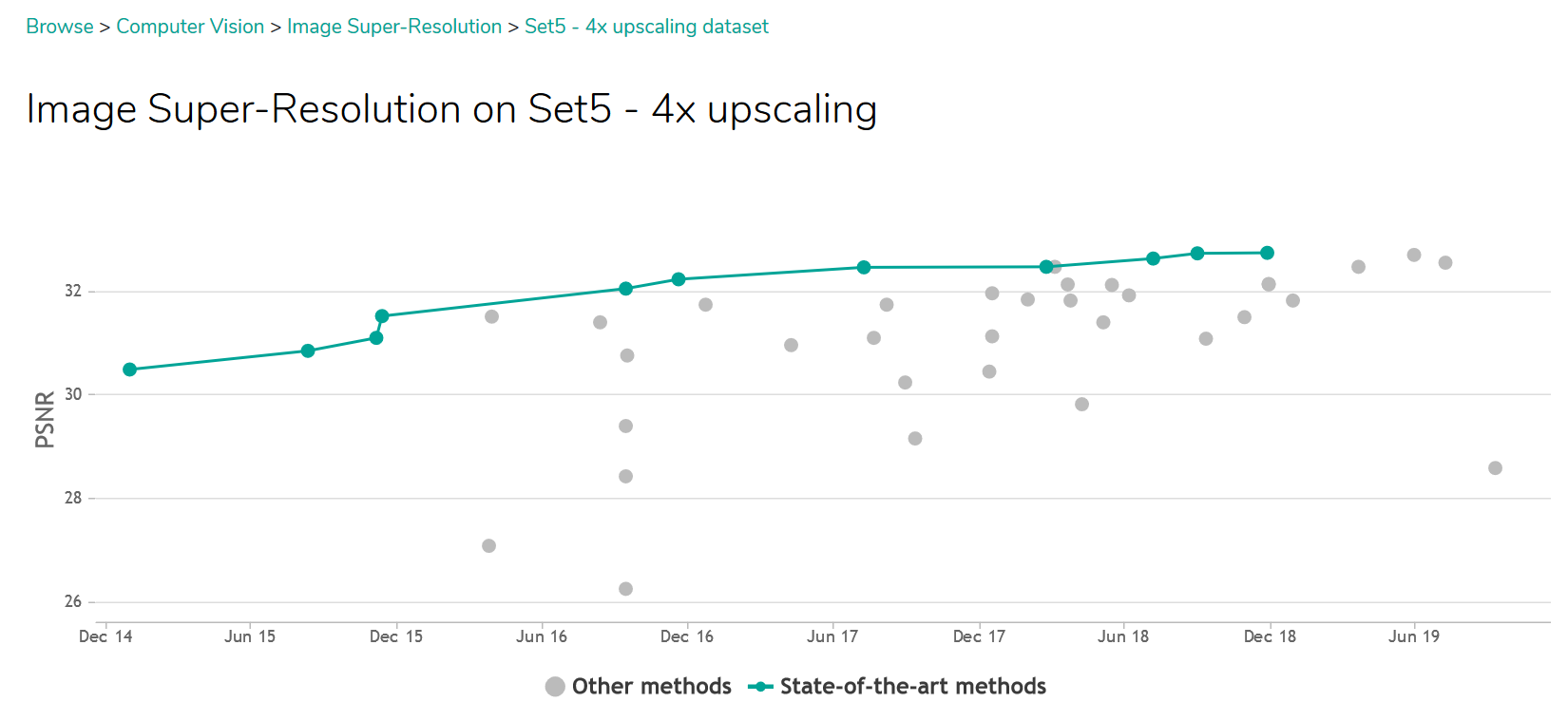
Figure 4 - Classement "Set5 - 4x upscaling" - paperwithcode.com (05/11/2019)
Pour terminer, bien que la qualité d’une image est un critère subjectif, des mesures objectives doivent être utilisées non-seulement pour entraîner les algorithmes (par apprentissage profond), mais également pour les comparer de manière objective. Néanmoins, ces mesures ne reflètent pas la réalité, car elles sont généralement basées sur une comparaison d’une image de bonne qualité à une image de qualité artificiellement réduite. Plus de détails sur l’entraînement des algorithmes par apprentissage profond, et des mesures de qualité de reconstruction peuvent se trouver ici.
Des licences hétérogènes et parfois contraignantes
Outre les contraintes dus aux outils et à la variabilité des performances, la réutilisation de travaux de l’état de l’art peut être soumise à des contraintes légales, régulés par des termes de licence, définissant les droits de réutilisation et de modification d’un projet. Certaines licences rendent des projets “libres de droits”, ce qui signifie que n’importe qui peut les réutiliser, les modifier, peu importe le contexte. Les licences libres de droits les plus couramment utilisées pour des programmes informatiques sont MIT, Apache et GPL. D’autres licences permettent la réutilisation en ajoutant certaines contraintes, comme une utilisation non-commerciale (e.g.: CC-BY-NC). Certains projets ont aussi une licence ad-hoc (personnalisée), comme par exemple Neural Nearest Neighbors Networks (NeurIPS, 2018), qui interdit également une utilisation commerciale de leur code. Enfin, d’autre projets n’incluent simplement pas de licence, les rendant ainsi simplement visible publiquement, mais concrètement inutilisables dans le développement d’un nouveau projet sous licence.
Un domaine en pleine expansion
L’utilisation des réseaux de neurones profonds dans la recherche, et en particulier dans le traitement d’images est actuellement un champ de recherche particulièrement en mouvement. L’état de l’art évolue rapidement. A titre d’exemple, lors de la phase de ce projet portant sur la comparaison d’algorithmes de super-résolution (voir ici), l’algorithme ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks (ECCV, 2018) était premier dans la plupart des classements. Ses performances semblent néanmoins avoir été surpassées depuis, par une autre algorithme: Second-Order Attention Network for Single Image Super-Resolution (CVPR 2019). Cependant, ce dernier n’a a l’heure actuelle aucune licence spécifiée (son utilisation n’est donc pas officiellement libre de droit).
Une sélection d’algorithmes libres de droits, utilisables, et compatibles
Dans ce projet, nous avons tenté d’obtenir un compromis entre un pipeline de restauration d’images à la fois générique et efficace. Un ensemble d’algorithmes implémentant différentes techniques de restauration d’image ont été sélectionnés de manière à fonctionner ensemble dans un même programme, à donner un résultat le plus robuste et générique possible, et réutilisable en pratique (i.e. libre de droits, et facile à mettre en œuvre).
Ainsi, pour chacune des quatre techniques évoquées plus haut, une analyse comparative de différents algorithmes a été réalisée.
La plupart des algorithmes ont été identifiés par une recherche systématique sur le site paperswithcode.com dans les catégories respectives, ou directement sur le site github.com, le site d’hébergement de référence de codes publics.
Réduction de bruit gaussien
De nombreux classements concernant la réduction de bruit sont accessibles sur: https://paperswithcode.com/task/image-denoising
Ces classements se distinguent par les jeux d’images de test utilisés ( BSD ou Urban100), et par l’amplitude du bruit gaussien (représenté par sont écart-type sigma) simulé dans ces images, et réduit ensuite par les algorithmes. Le jeu d’images BSD contient des images de scènes naturelles assez variées [[1][1]], et semble plus générique que le Urban100, qui se limite à des paysages urbains, principalement des images d’immeubles aux profils très réguliers.
Parmi les classements basés sur BSD, les classements BSD68 sigma50, BSD68 sigma25 et BSD68 sigma15 ont été retenus, car ils contiennent un plus large nombre d’algorithmes testés. Les deux derniers ont été testé sur des images avec une simulation de bruit plus “réaliste” (sigma = 25 et sigma = 15 respectivement), comme le montrent les exemples ci-dessous.

Figure 5 - Différents bruits gaussiens simulés dans une image (image source: ici)
{kind=link}
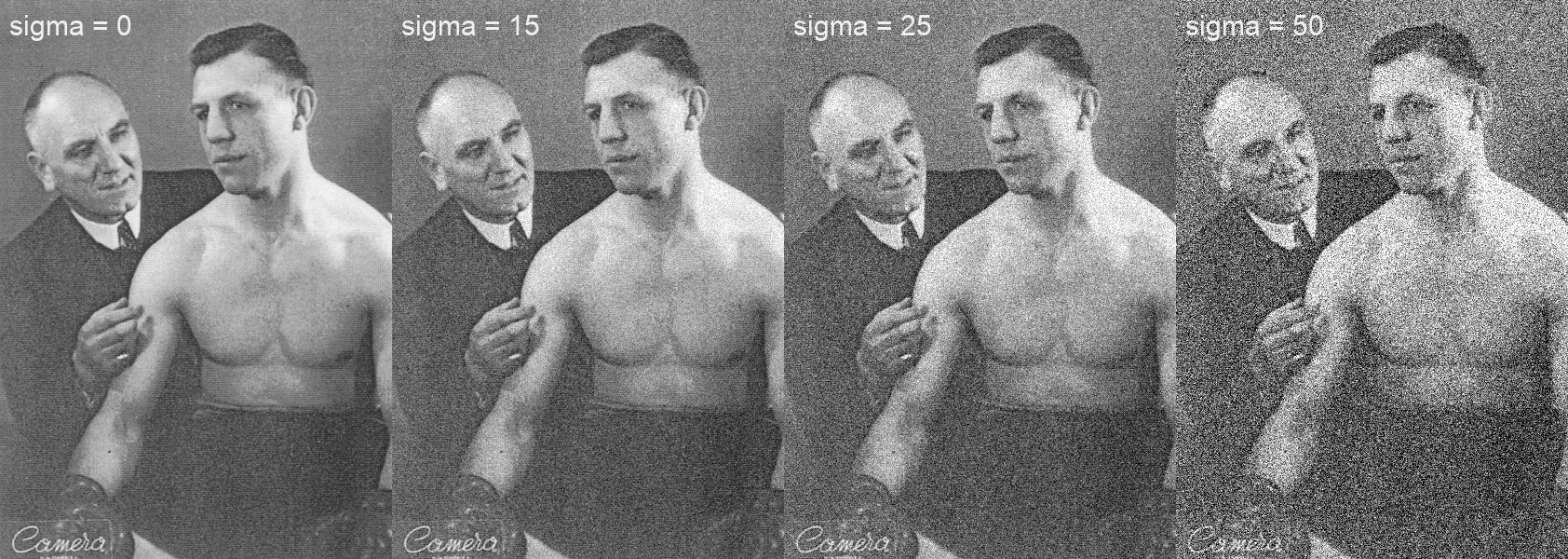
Figure 6 - Différents bruits gaussiens simulés dans une image (crédits image: Jean Vandendries)
Sur ces deux derniers classements, les seuls travaux proposant une licence libre de droits sont :
- NLRN - Non-Local Recurrent Network for Image Restoration (NeurIPS, 2018) - MIT
- DnCNN - Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising (TIP, 2017) - MIT (implémentation Keras uniquement)
D’après les places occupées par ces deux méthodes dans le classement, NLRN devrait donner les meilleurs résultats. Bien que la comparaison visuelle soit tout à fait subjective, NLRN semble effectivement donner de meilleurs résultats pour l’image de test. DNCNN semble lisser l’image et enlever une partie de sa texture. Cela se remarque particulièrement sur le bureau en bois présent dans l’image, ainsi que sur les cheveux devenus flous.
(NDLR: vous pouvez visualiser une version plus grande des images en cliquant dessus)

Figure 7 - Comparaison de méthodes de réduction de bruit gaussien (image source: ici)
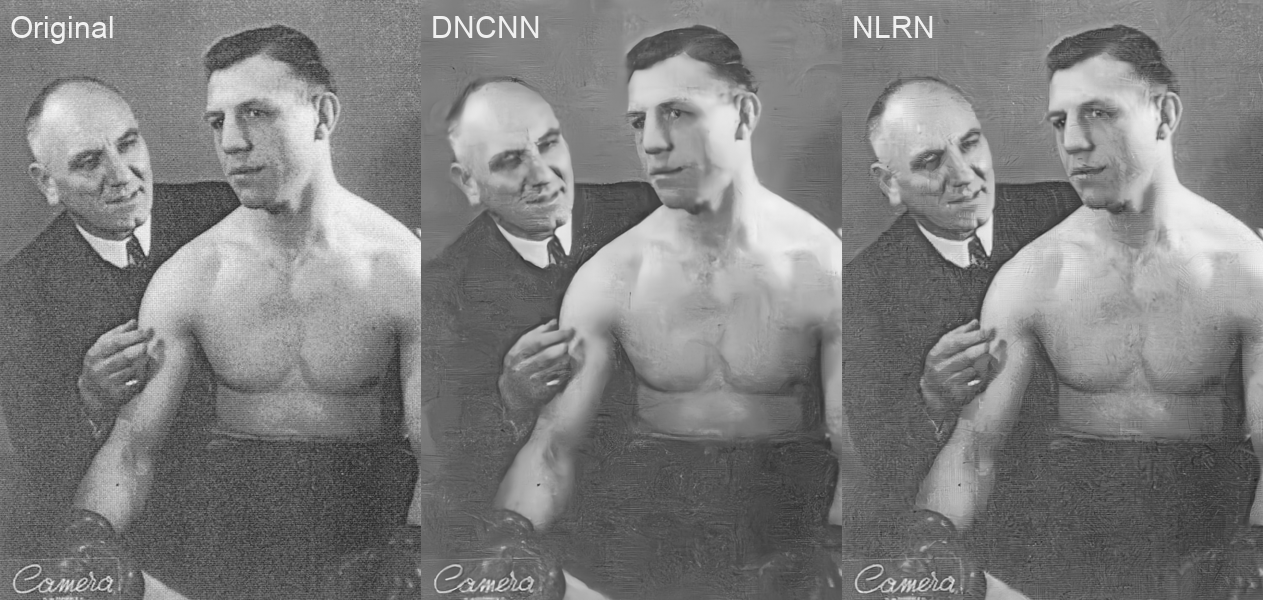
Figure 8 - Comparaison de méthodes de réduction de bruit gaussien (crédits image: Jean Vandendries)
Si seul le critère de qualité du résultat est pris en compte, NLRN semble donc plus efficace. Le résultats semble particulièrement bon sur l’image d’Anne Franck. Le résultat semble moins bon sur l’image de test, notamment à cause de l’apparition de certaines textures irréalistes dans les images résultantes. Le résultat de DNCNN semble caractérisé par une perte nette de relief, due à un lissage excessif.
Bien que la qualité de restauration soit le critère principal, le coût computationnel (ou le temps de calcul) d’une technique est un critère important en pratique, essentiellement pour une application sur un grand nombre d’image, ou en temps réel (cas plutôt rencontré dans d’autres contextes, tels que la surveillance vidéo ou satellite). Ainsi, d’un point de vue rapidité de calcul, le traitement a mis environ 4 secondes pour DNCNN, et 380 pour NLRN, pour une version d’image de petite taille (349x400 pixels). Bien sûr, l’algorithme peut être paramétré de manière à diminuer ce temps de traitement, au détriment de la qualité du résultat. Néanmoins, NLRN est particulièrement lent, en comparaison à DNCNN, et en comparaison avec les autres techniques dont nous parlons plus bas.
Réduction des rayures (stripe noise)
La réduction des rayures dans une image est une technique de restauration d’image plus rarement abordée dans la littérature. Selon le contexte, c’est pourtant une technique qui peut parfois être particulièrement efficace. Différentes implémentations de techniques de réductions de rayures ont été trouvées dans la littérature:
- SNRCNN - Single infrared image stripe noise removal using deep convolutional networks (IEEE Photonics Journal 2017)
- WDNN - Wavelet Deep Neural Network for Stripe Noise Removal (IEEE Access, 7, 2019)
Parmi ces quatre algorithmes, seule la dernière est implémentée en Python, et libre de droit (licence Apache 2.0. Cette méthode a donc été testée sur ces images aux bruits caractéristiques, avec des résultats intéressants.
La plupart de ces algorithmes ne suppriment que les rayures verticales, car elles ont été développées dans le contexte de traitement d’images obtenues par capteurs infrarouges, dont les rayures verticales sont un bruit caractéristique. Bien que ces algorithmes sont au départ dédiés aux images infrarouges, ils ont néanmoins un intérêt tout particulier dans nos images historiques.
Afin d’obtenir un algorithme libre de droit, et généralisé aux image historiques, nous avons adapté l’algorithme WDNN, de manière à éliminer à la fois les rayures verticales et horizontales.
Lors des différents tests que nous avons réalisés, nous avons pu constater que dans certains cas, l’algorithme de réduisait que partiellement les rayures des images. Nous avons alors testé une application séquentielle multiple de notre version adaptée de WDNN, réduisant successivement les rayures verticales et horizontales. Nous avons pu constater que cette application multiple permettait dans certains cas d’améliorer la suppression des rayures. Par ailleurs, aucune détérioration de l’image (apparition d’artéfacts) n’est constatée.
D’un point de vue coût computationnel, WDNN est très léger en comparaison à NLRN (réduction de bruit). L’ordre de grandeur pour une image de taille moyenne (500x500) est de 0.1 seconde, ce qui rend adéquate une utilisation multiple de cette technique.

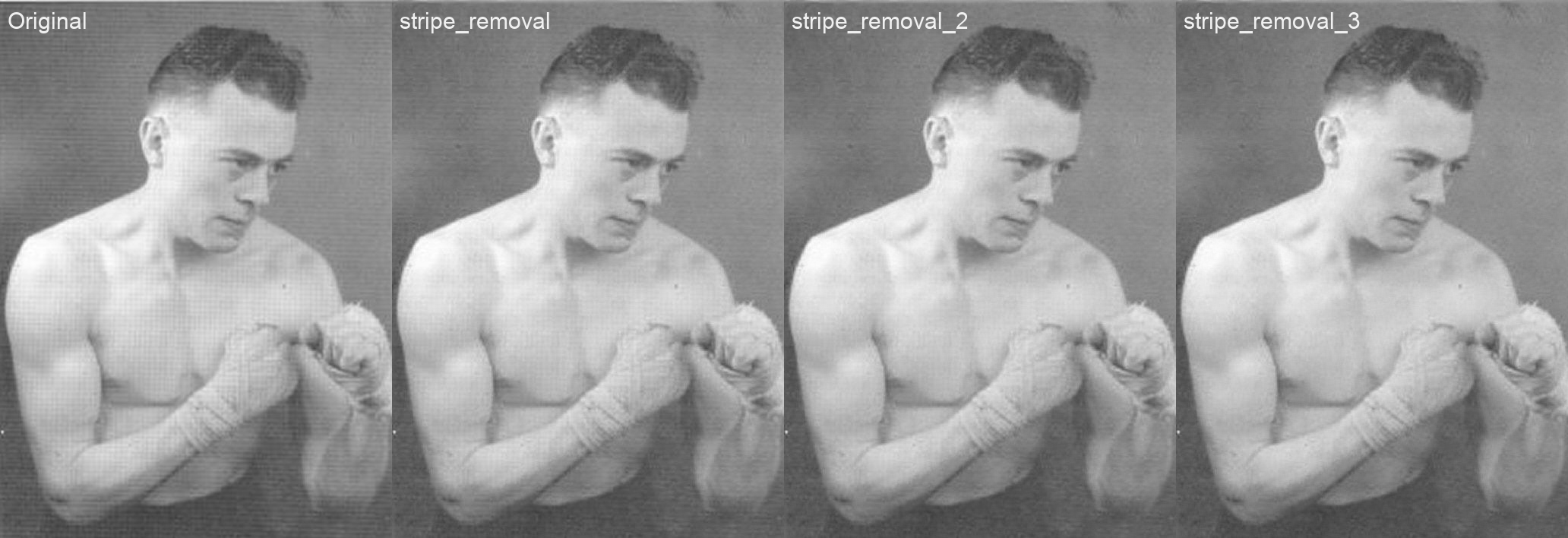
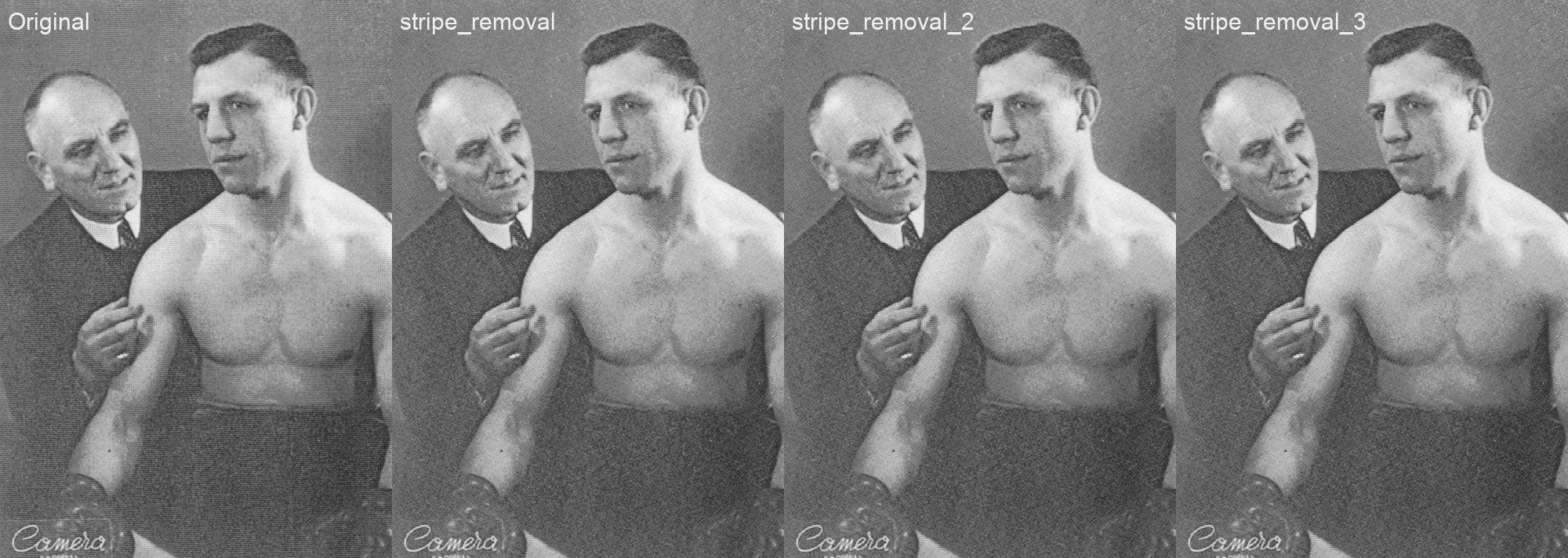
Figure 9 - Comparaison de méthodes de réduction de rayures (crédits image: Jean Vandendries).
Colorisation
La colorisation ne permet pas de supprimer des artéfacts, mais bien d’ajouter de l’information en transformant une image à un seul canal (monochrome) en une image à trois canaux (RGB, i.e. rouge, vert et bleu), permettant d’ajouter de la couleur aux images.
Trois techniques de colorisation ont été trouvées dans la littérature, proposant une implémentation open-source en python :
- Zhang2016 - Real-Time User-Guided Image Colorization with Learned Deep Priors (SIGGRAPH 2017)
- Deep Koalarization: Image Colorization using CNNs and Inception-ResNet-v2 (arXiv 2017)
- DeOlfidy (NoGAN) - A Deep Learning based project for colorizing and restoring old images (and video!) (github 2018)
La deuxième ne fournit pas de modèle pré-entraîné, et n’est donc pas directement utilisable (elle ne remplit donc pas directement nos critères de sélection). Elle a donc temporairement été exclue.
L’implémentation actuelle du premier modèle (Zhang2016) est basée sur une ancienne version de Python (v2), ce qui ne le rend donc pas directement compatible avec les autres, toutes implémentées en Python v3. Elle a néanmoins été testée pour comparaison avec la méthode DeOldify. Ce dernier modèle, plus récent, se base sur une architecture de réseau neuronal plus récente, appelée Réseaux Antagornistes Génératifs (Generative Adversarial Networks - GAN). Plus d’informations sur cette architecture peut être lue dans l’article sur la super-résolution suivant.
La figure suivante montre une comparaison des deux algorithmes sélectionnés. L’utilisation directe de l’implémentation de Zhang2016 présente une limitation importante: le résultat obtenu est une image de taille 256x256, quelque soit la taille de l’image originale. ainsi, dans la figure présentée ci-dessous, nous avons dû redimensionner le résultat pour obtenir la taille d’origine. Néanmoins, une partie de l’information a été perdue, résultant en une image moins nette.



Figure 10 - Comparaison de méthodes de réduction de rayures (crédits image: Jean Vandendries).
Concernant les couleurs, la comparaison ne peut être que subjective. Néanmoins, Zhang2016 semble donner des résultats limités, et laisse à certains endroits des zones encore grisâtres (voir par exemple le bras gauche de Zéphirin Gillain, première image, ainsi que la tête et l’épaule droite de Pol Goffaux, troisième image). En tout subjectivité, les résultats de DeOldify sont impressionnants, bien qu’imparfaits. On peut remarquer la couleure légèrement bleutée de la jambe droite de Zéphirin Gillain (premier boxeur), et le fond verdâtre teinté de rouge dans la deuxième image (NDLR, pour sa défense, je n’ai aucune idée de la couleur réelle non-plus).
En outre, DeOldify a également l’avantage d’être configurable: un facteur de rendu permet d’obtenir des couleurs plus ou moins vives (souvent au dépend du réalisme).
Super-résolution
La super-résolution permet également d’inférer de l’information supplémentaire à partir de l’image d’origine. Dans ce cas-ci, ce ne sont pas des couleurs qui sont inventées, mais bien des pixels, permettant d’augmenter artificiellement la taille, et a fortiori les détails d’une image.
Nous avons déjà présenté une comparaison de différents algorithmes de super-résolution dans un autre article de blog. Nous y avons en effet comparé six algorithmes différents, et avons finalement sélectionné l’algorithme ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks (ECCV, 2018), qui obtenait à l’époque (juin 2019) la première place dans plusieurs classements (Figure 11):
/Whitepapersuperresolution_fichiers/image7.png)
Figure 11 - Etat de l’art de la super-résolution d'images, recensé sur paperswithcode.com. SRGAN + Residual-in-Rseidual Dense Block (ESRGAN) se retrouvait à la première place sur la plupart des benchmarks (juin 2019).
Comme expliqué dans l’article de blog susmentionné, les performances de ces algorithmes sont prometteuses, mais instables. Autrement dit, les détails générés par ces techniques sont parfois peu réalistes.